8월 13일 - image retreival & pose estimation
8월 13일 - image retreival & pose estimation
run_vis.py, visual_localization.py
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
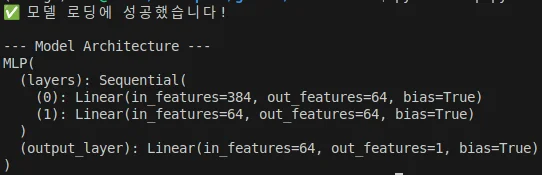
# run_vis.py
import argparse
import os
import sys
import cv2
import torch
import torch.nn.functional as F
import numpy as np
from src import config
# VisualLocalization 클래스를 src/visual_localization.py 로 두었다고 가정
from src.visual_localization import VisualLocalization
def setup_seed(seed: int):
torch.manual_seed(seed)
torch.cuda.manual_seed_all(seed)
np.random.seed(seed)
def img_to_tensor_bgr(img_bgr: np.ndarray, device: str | torch.device):
"""OpenCV BGR 이미지를 (1,3,H,W) torch.FloatTensor[0..1] 로 변환"""
if img_bgr is None:
raise FileNotFoundError("Failed to read image (cv2.imread returned None).")
img_rgb = cv2.cvtColor(img_bgr, cv2.COLOR_BGR2RGB)
ten = torch.from_numpy(img_rgb).permute(2, 0, 1).unsqueeze(0).float() / 255.0
return ten.to(device if isinstance(device, torch.device) else torch.device(device))
def find_image_by_frame_id(images_dir: str, frame_id: int, exts=(".png", ".jpg", ".jpeg", ".bmp")) -> str | None:
"""zero-pad 5자리 파일명 규칙(00000.png 등)을 우선 시도하고, 실패 시 확장자 전수 검사"""
fname_5 = f"{frame_id:05d}"
for ext in exts:
p = os.path.join(images_dir, fname_5 + ext)
if os.path.isfile(p):
return p
# 폴더 전체에서 해당 숫자를 포함한 파일명 탐색 (fallback)
try:
for f in sorted(os.listdir(images_dir)):
name, ext = os.path.splitext(f)
if ext.lower() in exts and any(ch.isdigit() for ch in name):
if str(frame_id) in name:
return os.path.join(images_dir, f)
except Exception:
pass
return None
def main():
parser = argparse.ArgumentParser(description="Visual localization (retrieval) viewer")
parser.add_argument("config", type=str, help="Path to config yaml")
parser.add_argument("--dbdir", type=str, default=None,
help="Path to DB features (.npz/.npy). "
"Default: {output}/{scene}/mono_priors/features")
parser.add_argument("--images_dir", type=str, required=True,
help="Path to original RGB frames directory")
parser.add_argument("--query", type=str, required=True, help="Path to query image")
parser.add_argument("--topk", type=int, default=5, help="Top-K retrieval")
parser.add_argument("--tstamp", type=int, default=0, help="Query pseudo index (for naming)")
args = parser.parse_args()
# Load cfg
cfg = config.load_config(args.config)
setup_seed(int(cfg.get("setup_seed", 42)))
device = cfg.get("device", "cuda:0")
if args.dbdir is None:
args.dbdir = os.path.join(cfg["data"]["output"], cfg["scene"], "mono_priors", "features")
print(f"[INFO] Using DB dir: {args.dbdir}")
print(f"[INFO] Images dir : {args.images_dir}")
print(f"[INFO] Device : {device}")
# Init localizer
vl = VisualLocalization(cfg, dbdir=args.dbdir, device=device)
# Load & show query image
q_bgr = cv2.imread(args.query, cv2.IMREAD_COLOR)
if q_bgr is None:
print(f"[ERR] Failed to read query image: {args.query}")
sys.exit(1)
cv2.imshow("Query", q_bgr)
cv2.waitKey(1)
# Make tensor and retrieve
q_tensor = img_to_tensor_bgr(q_bgr, device=device) # (1,3,H,W), float32 [0..1]
hits = vl.retreival(q_tensor, tstamp=args.tstamp, topk=args.topk)
out = vl.localize_with_vggt(
query_path=args.query,
retrieval_results=hits,
est_pose_txt= os.path.join(args.dbdir,"traj", "est_poses_full.txt"),
images_dir=args.images_dir,
use_topk=args.topk,
)
T_WC_q = out["T_WC_q"]
print("Query world pose (4x4, camera→world):\n", T_WC_q)
print("scale:", out["scale"], "used refs:", out["used_refs"])
# Print and show results
print("\n[RESULT] Top-{} retrieval:".format(args.topk))
for h in hits:
rid = h["frame_id"]
sim = h["similarity"]
fpath = find_image_by_frame_id(args.images_dir, rid)
print(f" - rank {h['rank']:>2} | frame_id {rid:>6} | sim {sim:.4f} | feat {h['feature_path']}")
if fpath is None:
print(f" [WARN] Could not locate RGB for frame_id={rid} in {args.images_dir}")
continue
img = cv2.imread(fpath, cv2.IMREAD_COLOR)
if img is None:
print(f" [WARN] Failed to read: {fpath}")
continue
win_name = f"Top-{h['rank']} | frame_id={rid}"
cv2.imshow(win_name, img)
cv2.waitKey(10)
print("\n[INFO] Press any key on an image window to exit...")
cv2.waitKey(0)
cv2.destroyAllWindows()
if __name__ == "__main__":
main()
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
256
257
258
259
260
261
262
263
264
265
266
267
268
269
270
271
272
273
274
275
276
277
278
279
280
281
282
283
284
285
286
287
288
289
290
291
292
293
294
295
296
297
298
299
300
301
302
303
304
305
306
307
308
309
310
311
312
313
314
315
316
317
318
319
320
321
322
323
324
325
326
327
328
329
330
331
332
333
334
335
336
337
338
339
340
341
342
343
344
345
346
347
348
349
350
351
352
353
354
355
356
357
358
359
360
361
362
363
#localization.py
import torch
import torch.nn.functional as F
import os, re, glob, json
from pathlib import Path
from typing import List, Dict, Tuple
import numpy as np
from src.utils.mono_priors.img_feature_extractors import predict_img_features, get_feature_extractor
from thirdparty.vggt.vggt.models.vggt import VGGT
from thirdparty.vggt.vggt.utils.load_fn import load_and_preprocess_images_square
from thirdparty.vggt.vggt.utils.pose_enc import pose_encoding_to_extri_intri
try:
import faiss
_HAS_FAISS = True
except Exception:
_HAS_FAISS = False
def _mean_pool_and_norm(feat: torch.Tensor) -> np.ndarray:
"""feat: (H',W',C) or (N,C) -> (C,) L2-normalized float32 numpy"""
if feat.ndim == 3:
feat = feat.reshape(-1, feat.shape[-1])
vec = feat.mean(dim=0)
vec = vec / (vec.norm() + 1e-12)
return vec.cpu().float().numpy()
def _parse_id(path: str) -> int:
m = re.search(r'(\d+)', os.path.basename(path))
return int(m.group(1)) if m else -1
def _quat_xyzw_to_R(q):
"""q = (x,y,z,w) -> 3x3 회전행렬"""
import numpy as _np
x,y,z,w = q
# scipy 없이 직접 구성
# 참고: https://en.wikipedia.org/wiki/Rotation_matrix#Quaternion
xx, yy, zz = x*x, y*y, z*z
xy, xz, yz = x*y, x*z, y*z
wx, wy, wz = w*x, w*y, w*z
R = _np.array([
[1-2*(yy+zz), 2*(xy-wz), 2*(xz+wy)],
[2*(xy+wz), 1-2*(xx+zz), 2*(yz-wx)],
[2*(xz-wy), 2*(yz+wx), 1-2*(xx+yy)],
], dtype=_np.float64)
return R
def _to_T(Rwc, twc):
T = np.eye(4, dtype=np.float64)
T[:3,:3] = Rwc
T[:3, 3] = twc
return T
def _read_est_poses_full(txt_path: str) -> Dict[int, np.ndarray]:
"""
est_poses_full.txt: idx tx ty tz qx qy qz qw (카메라→월드 라고 가정)
반환: frame_id -> 4x4 T_W←C
"""
id2T = {}
with open(txt_path, 'r') as f:
for line in f:
ss = line.strip().split()
if len(ss) != 8:
continue
idx = int(ss[0])
tx,ty,tz = map(float, ss[1:4])
qx,qy,qz,qw = map(float, ss[4:8])
Rwc = _quat_xyzw_to_R((qx,qy,qz,qw))
twc = np.array([tx,ty,tz], dtype=np.float64)
id2T[idx] = _to_T(Rwc, twc)
return id2T
def _worldcam_extrinsic_to_4x4(E: np.ndarray) -> np.ndarray:
"""
VGGT extrinsic: world->camera, shape (3,4) or (4,4)
"""
if E.shape == (3,4):
T = np.eye(4, dtype=np.float64)
T[:3,:4] = E
return T
assert E.shape == (4,4)
return E.astype(np.float64)
def _rel_cam_to_cam(E_from: np.ndarray, E_to: np.ndarray) -> np.ndarray:
"""
둘 다 world->camera. T_from→to = E_to · E_from^{-1}
"""
return E_to @ np.linalg.inv(E_from)
def _scale_translation(T: np.ndarray, s: float) -> np.ndarray:
Tout = T.copy()
Tout[:3,3] *= s
return Tout
def _find_image_by_id(images_dir: str, frame_id: int) -> str | None:
"""
features의 00037.npy -> 이미지 파일명을 robust하게 탐색.
시도: frame_%05d.{png,jpg,jpeg}, %05d.{png,...}, img_%05d, image_%05d
마지막으로 디렉토리 전체에서 frame_id 숫자 포함 파일 grep.
"""
DID = f"{frame_id:05d}"
candidates = []
stems = [f"frame_{DID}", DID, f"img_{DID}", f"image_{DID}"]
exts = ["png","jpg","jpeg","bmp"]
for s in stems:
for e in exts:
candidates.append(Path(images_dir)/f"{s}.{e}")
for c in candidates:
if c.exists():
return str(c)
# fallback: 숫자 포함하는 파일 중 최근/가장 짧은 이름
g = []
for e in exts:
g += glob.glob(str(Path(images_dir)/f"*{DID}*.{e}"))
if g:
g.sort(key=lambda p: (len(Path(p).name), p))
return g[0]
return None
def _load_vggt(device="cuda"):
model = VGGT()
_URL = "https://huggingface.co/facebook/VGGT-1B/resolve/main/model.pt"
sd = torch.hub.load_state_dict_from_url(_URL)
model.load_state_dict(sd)
model.eval().to(device)
return model
def _run_vggt_extrinsics(model, paths: List[str], device="cuda",
load_res=1024, run_res=518) -> np.ndarray:
"""
paths: 이미지 리스트
반환: extrinsic (N, 3, 4) world->camera
"""
imgs, _ = load_and_preprocess_images_square(paths, load_res) # (N,3,H,W) in [-1,1] norm style (유틸 내부)
imgs = imgs.to(device)
with torch.no_grad():
with torch.cuda.amp.autocast(dtype=(torch.bfloat16 if torch.cuda.get_device_capability()[0] >= 8 else torch.float16)):
# VGGT는 내부에서 518로 리사이즈해 camera/depth 추정
x = F.interpolate(imgs, size=(run_res, run_res), mode="bilinear", align_corners=False)
x = x[None] # aggregator가 [B=1, N, 3, H, W] 꼴로 쓰는 코드
aggregated_tokens_list, ps_idx = model.aggregator(x)
pose_enc = model.camera_head(aggregated_tokens_list)[-1]
extrinsic, intrinsic = pose_encoding_to_extri_intri(pose_enc, x.shape[-2:])
# (1,N,3,4)->(N,3,4)
return extrinsic.squeeze(0).cpu().numpy()
def _estimate_scale_from_refs(E_refs: List[np.ndarray],
T_WC_refs: List[np.ndarray]) -> float:
"""
ref가 2장 이상일 때 모든 쌍 (i,j)로 스케일 추정 후 중간값 반환.
스케일 s = ||baseline_world|| / ||baseline_vggt||
"""
baselines = []
n = len(E_refs)
for i in range(n):
for j in range(i+1, n):
# VGGT 상대 (i->j)
T_ij = _rel_cam_to_cam(_worldcam_extrinsic_to_4x4(E_refs[i]),
_worldcam_extrinsic_to_4x4(E_refs[j]))
b_vggt = np.linalg.norm(T_ij[:3,3])
if b_vggt < 1e-8:
continue
# SLAM 세계에서 카메라 중심
Ci = T_WC_refs[i][:3,3]
Cj = T_WC_refs[j][:3,3]
b_world = np.linalg.norm(Cj - Ci)
if b_world < 1e-8:
continue
baselines.append(b_world / b_vggt)
if not baselines:
return 1.0
return float(np.median(baselines))
def _avg_pose_candidates(T_list: List[np.ndarray]) -> np.ndarray:
"""
여러 ref로부터 얻은 후보 T_WC_q를 단순 결합.
여기서는 간단히 '중간값 번역', 회전은 첫 번째 사용(실전은 SO(3) 평균 권장).
"""
if len(T_list) == 1:
return T_list[0]
ts = np.stack([T[:3,3] for T in T_list], axis=0)
t_med = np.median(ts, axis=0)
T = T_list[0].copy()
T[:3,3] = t_med
return T
class VisualLocalization:
"""
this class is for re-localization in map that is made with wildgs slam
"""
def __init__(self, cfg, dbdir, thresh=2.5, device="cuda:0"):
self.cfg = cfg
self.dbdir = dbdir
self.thresh = thresh
self.device = device
self.feat_extractor = get_feature_extractor(cfg)
self.MEAN = torch.as_tensor([0.485, 0.456, 0.406], device=self.device)[:, None, None]
self.STDV = torch.as_tensor([0.229, 0.224, 0.225], device=self.device)[:, None, None]
self._db_vecs = None # (N,C) float32
self._db_ids = None # (N,)
self._db_paths = None # (N,)
self._index = None # faiss index
def _load_one_feature(self, path: str) -> torch.Tensor:
"""
DB 파일을 로드해 torch.Tensor로 반환.
지원: .npy, .npz (npz는 첫 번째 key를 사용)
예상 shape: (H',W',C) 또는 (N,C)
"""
if path.endswith(".npz"):
z = np.load(path)
# 키가 'feat' 등일 수도, arr_0일 수도 있으므로 첫 키 사용
key = list(z.files)[0]
arr = z[key]
else: # .npy
arr = np.load(path)
return torch.from_numpy(arr)
def _build_db(self):
paths = sorted(glob.glob(os.path.join(self.dbdir,"mono_priors","features", "*.npz")) +
glob.glob(os.path.join(self.dbdir,"mono_priors","features", "*.npy")))
if not paths:
raise FileNotFoundError(f"No .npz/.npy features in {self.dbdir}")
vecs, ids = [], []
for p in paths:
feat = self._load_one_feature(p).float() # (H',W',C) or (N,C)
vec = _mean_pool_and_norm(feat) # (C,)
vecs.append(vec)
ids.append(_parse_id(p))
self._db_vecs = np.stack(vecs, axis=0).astype("float32") # (N,C)
self._db_ids = np.asarray(ids, dtype=np.int64)
self._db_paths = np.asarray(paths, dtype=object)
if _HAS_FAISS:
d = self._db_vecs.shape[1]
index = faiss.IndexFlatIP(d) # 코사인=내적 (벡터는 L2정규화됨)
index.add(self._db_vecs)
self._index = index
def localize_with_vggt(self,
query_path: str,
retrieval_results: List[Dict],
est_pose_txt: str,
images_dir: str,
use_topk: int = 2) -> Dict:
"""
VGGT로 (쿼리 + ref들) 포즈를 추정하고, SLAM 월드로 끌어올려 쿼리의 월드포즈를 추정.
반환: dict( T_WC_q, scale, used_refs, per_ref )
"""
assert len(retrieval_results) >= 1, "retrieval 결과가 비었습니다."
# 0) 레퍼런스 이미지 경로 수집
refs = retrieval_results[:use_topk]
ref_ids = []
ref_imgs = []
for r in refs:
fid = int(r["frame_id"])
path = _find_image_by_id(images_dir, fid)
if path is None:
print(f"[WARN] ref frame_id={fid} 의 RGB를 찾지 못했습니다. 스킵.")
continue
ref_ids.append(fid)
ref_imgs.append(path)
if not ref_imgs:
raise FileNotFoundError("레퍼런스 RGB를 하나도 찾지 못함.")
# 1) SLAM 월드포즈 로드 (camera→world)
id2T_WC = _read_est_poses_full(est_pose_txt)
T_WC_refs = []
for fid in ref_ids:
if fid not in id2T_WC:
raise KeyError(f"est_pose_full.txt에 frame_id={fid} 가 없습니다.")
T_WC_refs.append(id2T_WC[fid])
# 2) VGGT 로드 & extrinsic 추정 (world→camera)
device = self.device if torch.cuda.is_available() else "cpu"
model = _load_vggt(device=device)
# ref + query
all_paths = ref_imgs + [query_path]
E = _run_vggt_extrinsics(model, all_paths, device=device) # (N,3,4)
# 분리
E_refs = [E[i] for i in range(len(ref_imgs))]
E_q = E[len(ref_imgs)]
# 3) 스케일 추정 (ref가 2장 이상일 때 권장)
s = _estimate_scale_from_refs(E_refs, T_WC_refs)
# 4) 각 ref마다 쿼리 월드포즈 후보 계산
T_WC_q_candidates = []
per_ref = []
for i, (E_r, T_WC_r, fid) in enumerate(zip(E_refs, T_WC_refs, ref_ids)):
T_r_to_q = _rel_cam_to_cam(_worldcam_extrinsic_to_4x4(E_r),
_worldcam_extrinsic_to_4x4(E_q))
T_r_to_q_scaled = _scale_translation(T_r_to_q, s)
T_WC_q = T_WC_r @ np.linalg.inv(T_r_to_q_scaled)
T_WC_q_candidates.append(T_WC_q)
per_ref.append({
"ref_frame_id": fid,
"T_r_to_q": T_r_to_q,
"T_r_to_q_scaled": T_r_to_q_scaled,
"T_WC_r": T_WC_r,
"T_WC_q_candidate": T_WC_q
})
# 5) 후보 결합(간단 버전: 번역 중간값)
T_WC_q_final = _avg_pose_candidates(T_WC_q_candidates)
return {
"T_WC_q": T_WC_q_final, # 4x4 (camera→world)
"scale": s,
"used_refs": ref_ids,
"per_ref": per_ref,
}
@torch.no_grad()
def retreival(self, image: torch.Tensor, tstamp: int, topk: int = 5):
"""
image: (1,3,H,W) torch.Tensor (SLAM 파이프라인과 동일 스케일/정규화 전 입력)
"""
# 1) 쿼리 DINO feature 추출 (저장은 불필요)
q_feat = predict_img_features(
model=self.feat_extractor,
idx=tstamp,
input_tensor=image,
cfg=self.cfg,
device=self.device,
save_feat=False,
) # (H',W',C)
q_vec = _mean_pool_and_norm(q_feat) # (C,) float32
# 2) DB 준비
if self._db_vecs is None:
self._build_db()
# 3) 검색
if _HAS_FAISS and self._index is not None:
D, I = self._index.search(q_vec[None,:], topk) # 내적값 클수록 유사
sims = D[0]; inds = I[0]
else:
sims = (self._db_vecs @ q_vec).astype("float32")
inds = np.argsort(-sims)[:topk]
# 4) 결과 반환
results = []
for rank, i in enumerate(inds):
results.append({
"rank": rank+1,
"frame_id": int(self._db_ids[i]),
"feature_path": str(self._db_paths[i]),
"similarity": float(sims[rank] if _HAS_FAISS and self._index is not None else sims[i]),
})
return results
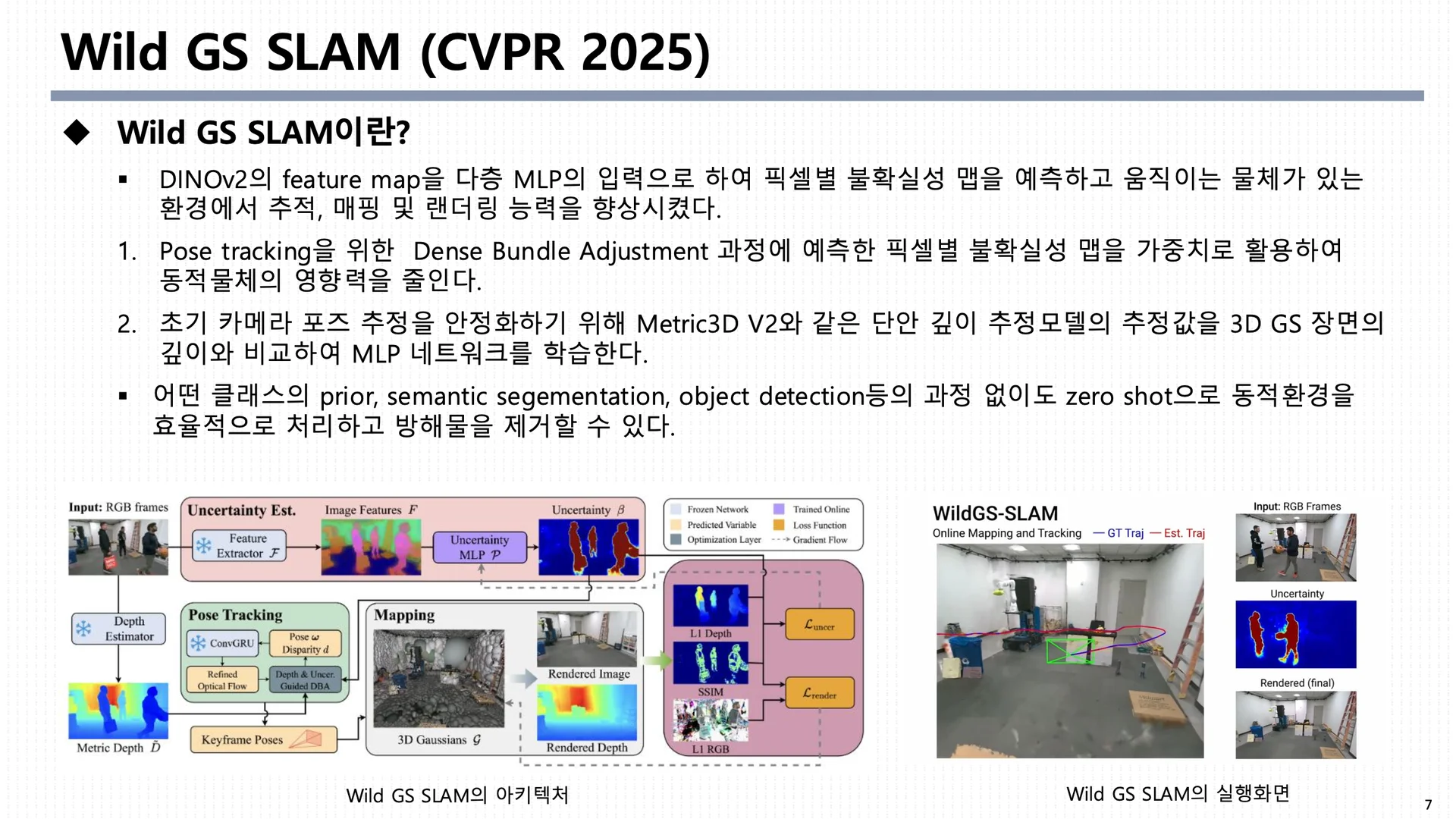
wild gs slam 결과물 분석
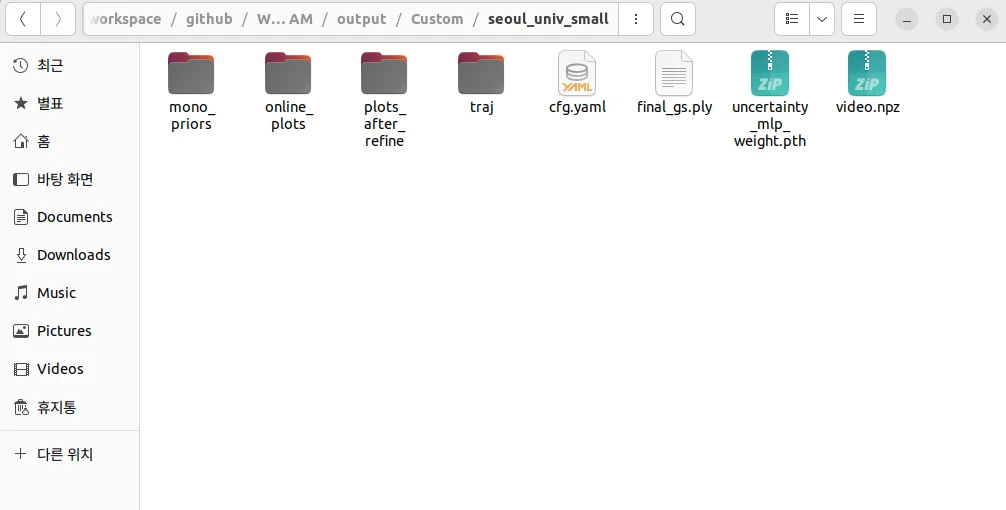


- mono_prios
- features : 입력으로 들어온 순차적인 이미지들의 DINOv2 feature이다. (H, W, C) 형태를 띄고 있다.

- features : 입력으로 들어온 순차적인 이미지들의 DINOv2 feature이다. (H, W, C) 형태를 띄고 있다.

- traj
- est_poses_full.txt : 슬램 맵에 쓰인 이미지들의 카메라 포즈이다. 순서대로 (frame_id, tx, ty, tz, qx, qy, qz, qw) 의 형식을 띈다.
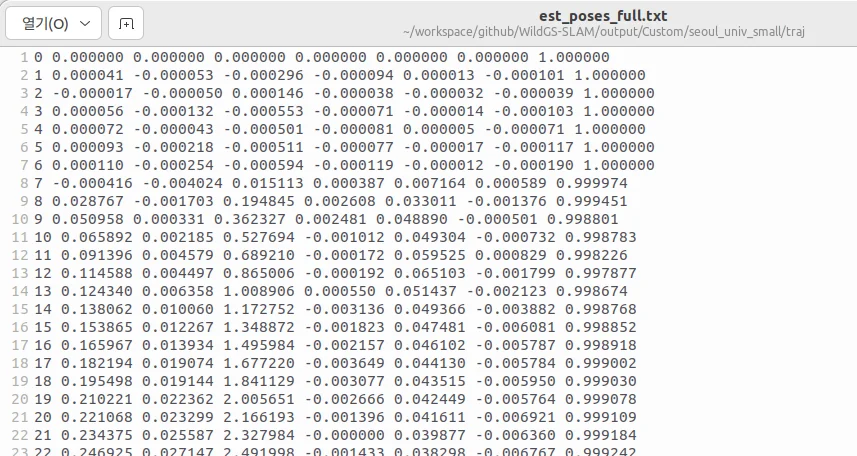
- est_poses_full.txt : 슬램 맵에 쓰인 이미지들의 카메라 포즈이다. 순서대로 (frame_id, tx, ty, tz, qx, qy, qz, qw) 의 형식을 띈다.
- plots_after_refine
- output.gif : 모든 입력 이미지에 대해 estimated depth와 rendered_depth, uncertainty map등의 결과를 한눈에 보여준다.
- output.gif : 모든 입력 이미지에 대해 estimated depth와 rendered_depth, uncertainty map등의 결과를 한눈에 보여준다.
- uncertainty_mlp_weight.pth : 파이토치 가중치로써 DINOv2를 입력으로 넣었을때 움직이는 물체를 감지하는 mlp이다.
- final_gs.ply : global slam map으로써 3d gaussian map이므로 ply형식이다. 3d viewer로 보았을 때 아래와 같이 보인다. 아마도 est_poses_full.txt의 카메라 포즈와 스케일이 동일 할 것 같다.

실험설정
- map을 제작되는데 사용되는 약 600장의 이미지와 나머지 쿼리 후보군 이미지 800장으로 데이터 셋 분류
- 1000장 이상으로 넘어갈 시 4070 ti super 그래픽카드의 16gb ram 초과 현상 발생
600 장으로 wildgs slam map작성
- map을 만드는데 사용된 이미지를 db에서 제거한 후 쿼리이미지로 사용하여 map 제작시의 카메라 포즈와 쿼리하여 찾은 카메라 포즈의 rotation과 transition 을 비교한다.
- ets_pose_full.txt와 query image의 $P_{4\times4}$ 를 비교한다.

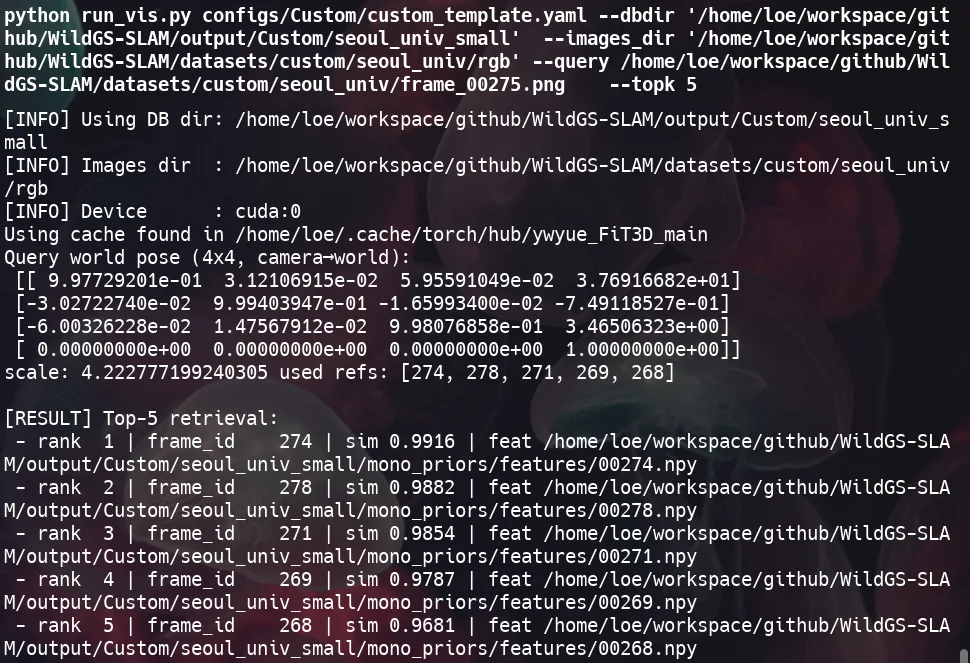

- ets_pose_full.txt와 query image의 $P_{4\times4}$ 를 비교한다.
This post is licensed under CC BY 4.0 by the author.