[Unitree Go2 part 1] Sim2Real 사연있습니다..
[Unitree Go2 part 1] Sim2Real 사연있습니다..
What is problem?

지난 시간에 로봇이 발을 떼지 않는 문제점을 발견하였다… 지난 3일간 여러가지 세팅으로 테스트를 반복해 보았다.
hypothesis 1.
로봇개가 발을 들도록 하는 reward setting이 잘못 되었다는 것이다. unitree_rl_lab에서 기본적으로 제공하던 관련 세팅은 아래와 같았다.
feet_air_time()
feet_air_time
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
def feet_air_time(
env: ManagerBasedRLEnv, command_name: str, sensor_cfg: SceneEntityCfg, threshold: float
) -> torch.Tensor:
"""Reward long steps taken by the feet using L2-kernel.
This function rewards the agent for taking steps that are longer than a threshold. This helps ensure
that the robot lifts its feet off the ground and takes steps. The reward is computed as the sum of
the time for which the feet are in the air.
If the commands are small (i.e. the agent is not supposed to take a step), then the reward is zero.
"""
# extract the used quantities (to enable type-hinting)
contact_sensor: ContactSensor = env.scene.sensors[sensor_cfg.name]
# compute the reward
first_contact = contact_sensor.compute_first_contact(env.step_dt)[:, sensor_cfg.body_ids]
last_air_time = contact_sensor.data.last_air_time[:, sensor_cfg.body_ids]
reward = torch.sum((last_air_time - threshold) * first_contact, dim=1)
# no reward for zero command
reward *= torch.norm(env.command_manager.get_command(command_name)[:, :2], dim=1) > 0.1
return reward
- 변수
- $t_{air, i}$: $i$번째 발이 공중에 떠 있었던 시간 (
last_air_time) - $C_i$ : $i$번째 발이 지면에 닿았는지 여부를 나타내는 이진 플래그 (0 또는 1) (
first_contact) - $\tau$: 보상을 주기 위한 최소 공중 체류 시간 임계값 (
threshold) - $\mathbf{v}_{cmd}$: 로봇에게 내려진 속도 명령 (x, y 평면 속도)
- $t_{air, i}$: $i$번째 발이 공중에 떠 있었던 시간 (
- reward
- $R_{air} = \sum_{i \in \text{feet}} (t_{air, i} - \tau) \cdot C_i$
- 즉, threshold 시간보다 길게 발을 들고 있는 발이 땅에 닿는 순간 보상을 준다.
기존에 0.1로 되어있던 이 가중치를 5.0으로 대폭 늘려 발을 드는것에 대한 보상을 크게 늘렸다.
feet_slide()
feet_slide()
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
def feet_slide(env, sensor_cfg: SceneEntityCfg, asset_cfg: SceneEntityCfg = SceneEntityCfg("robot")) -> torch.Tensor:
"""Penalize feet sliding.
This function penalizes the agent for sliding its feet on the ground. The reward is computed as the
norm of the linear velocity of the feet multiplied by a binary contact sensor. This ensures that the
agent is penalized only when the feet are in contact with the ground.
"""
# Penalize feet sliding
contact_sensor: ContactSensor = env.scene.sensors[sensor_cfg.name]
contacts = contact_sensor.data.net_forces_w_history[:, :, sensor_cfg.body_ids, :].norm(dim=-1).max(dim=1)[0] > 1.0
asset = env.scene[asset_cfg.name]
body_vel = asset.data.body_lin_vel_w[:, asset_cfg.body_ids, :2]
reward = torch.sum(body_vel.norm(dim=-1) * contacts, dim=1)
return reward
- 변수
- $v_{i, xy}$: $i$번째 발의 월드 좌표계 기준 수평 선속도 (
body_lin_vel_w[:, :, :2]) - $F_{i}$: $i$번째 발에 가해지는 지면 반력(Net force)의 크기
- $C_i$: 발이 지면에 닿아 있는지를 판단하는 이진 플래그 (Boolean)
- $I$: 접촉 판단 임계값 (코드에서는
1.0Newton)
- $v_{i, xy}$: $i$번째 발의 월드 좌표계 기준 수평 선속도 (
- reward
- $R_{slide} = \sum_{i \in \text{feet}} |v_{i, xy}| \cdot C_i$
- 즉, 발이 닿아있는 상태에서 foot에 속도가 들어가고 있다면 그 값에 음의 가중치를 곱해 negative reward를 주는 형식이다.
기존에 -0.1로 되어있던 이 가중치를 -1.0으로 대폭 늘렸다.
result
해당 세팅으로 학습을 진행한 후 test 해본 결과 simulation 상에서도 로봇이 걷지 못하는 문제점이 발생하였다…
hypothesis 1.
- feet air time이 땅에 발이 붙어서 0으로 들어가고 있었다. 아무래도 threshold를 낮춰주지 않아 로봇이 threshold보다 길게 발을 들어서 보상을 키우는 것 보다. 차라리 땅에서 발을 떼지않고 0의 보상을 받는게 이득이라고 판단한 것 같다.
- 바닥에 발을 붙이고 몸통만을 이리저리 움직이며 속도 명령에 따라 보상을 조금씩 받고 있었다. 아무래도 실제로 명령에 따라 움직이는 것보다 몸통만 흔드는 것이 보상이 더 컷나보다..
원인에 대해서 찾아보던 도중 굉장히 도움이 되는 issue를 발견하였다. 내용은 다음과 같았고 그에 따라서 설정을 변경해주었다.
- 단계별로 어려워지는 다른 terrian을 학습에 추가하여 로봇이 발을 들게 하는 요인을 만들어줄것
- 커리큘럼에 따라서 난이도를 조절하고 (height of terrian) 계단을 제외한 두가지 rough terrian을 추가하였다.
- 로봇의 usd file이 잘못되어 바닥에서 발이 떨어져도 자신의 calflower 부분과 foot부분이 contact 상태라는 것
- usd file관련된 이슈는 확인해본 결과 이미 고쳐졌는지 바닥에서 떨어지자 contact신호는 들어오지 않았다.
- feet과 관련된 보상중에 발을 특정 높이까지 들었을때 보상을 주는 feet clearance 함수를 새로 만들 것
- terrain이 추가된 이상 foot의 world z축을 기준으로 보상을 주기 보다는 로봇의 base와 foot간의 거리를 기준으로한 feet_height_body 함수를 새로 만들어 발을 특정 위치 이상으로 들도록 하였다.
feet_height_body
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25
def feet_height_body( env: ManagerBasedRLEnv, command_name: str, asset_cfg: SceneEntityCfg, target_height: float, tanh_mult: float, ) -> torch.Tensor: """Reward the swinging feet for clearing a specified height off the ground""" asset: RigidObject = env.scene[asset_cfg.name] cur_footpos_translated = asset.data.body_pos_w[:, asset_cfg.body_ids, :] - asset.data.root_pos_w[:, :].unsqueeze(1) footpos_in_body_frame = torch.zeros(env.num_envs, len(asset_cfg.body_ids), 3, device=env.device) cur_footvel_translated = asset.data.body_lin_vel_w[:, asset_cfg.body_ids, :] - asset.data.root_lin_vel_w[ :, : ].unsqueeze(1) footvel_in_body_frame = torch.zeros(env.num_envs, len(asset_cfg.body_ids), 3, device=env.device) for i in range(len(asset_cfg.body_ids)): footpos_in_body_frame[:, i, :] = quat_apply_inverse(asset.data.root_quat_w, cur_footpos_translated[:, i, :]) footvel_in_body_frame[:, i, :] = quat_apply_inverse(asset.data.root_quat_w, cur_footvel_translated[:, i, :]) foot_z_target_error = torch.square(footpos_in_body_frame[:, :, 2] - target_height).view(env.num_envs, -1) foot_velocity_tanh = torch.tanh(tanh_mult * torch.norm(footvel_in_body_frame[:, :, :2], dim=2)) reward = torch.sum(foot_z_target_error * foot_velocity_tanh, dim=1) reward *= torch.linalg.norm(env.command_manager.get_command(command_name), dim=1) > 0.1 reward *= torch.clamp(-env.scene["robot"].data.projected_gravity_b[:, 2], 0, 0.7) / 0.7 return reward
result
feet slid의 가중치를 -1.0에서 다시 -0.1로 되돌리고 threshold를 조금 낮추고 학습해보았다. 그 결과 로봇이 simulation 상에서 잘 걷게 되었다.

mujoco
이전에는 바로 sim2real이 되지 않을까 해서 deploy 해보았지만 보통은 isaaclab에서 학습하고 더 정교한 cpu기반 시뮬레이터인 mujoco에서 sim2sim 테스트를 해보곤 한다. 따라서 이번에 모델을 시뮬레이터 상에서 테스트 해보았다.
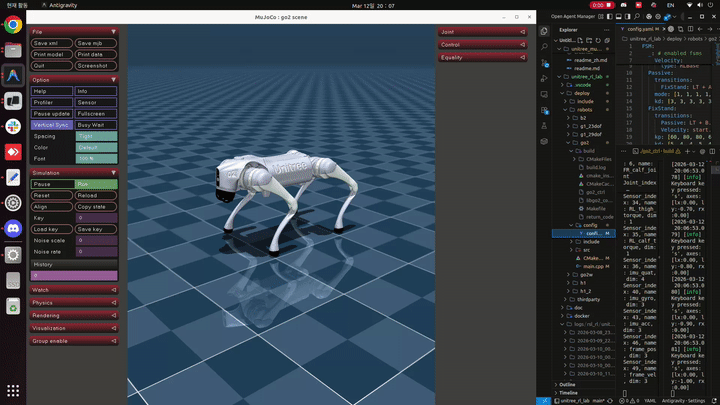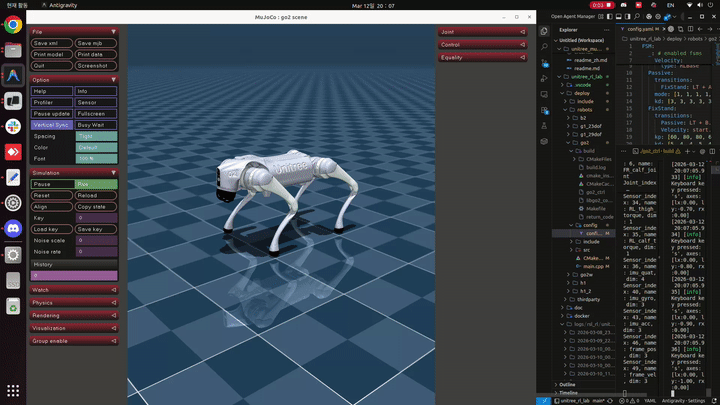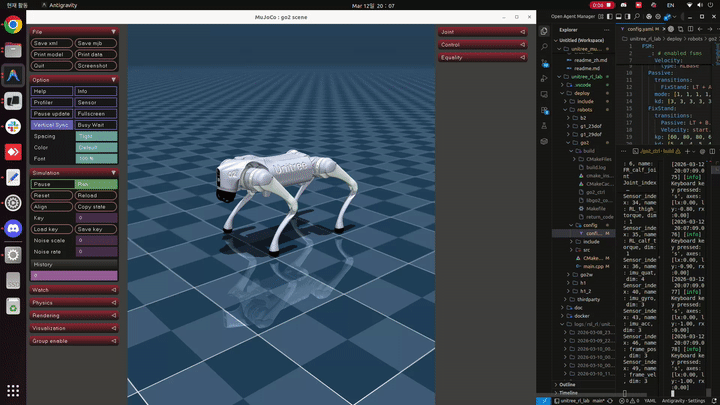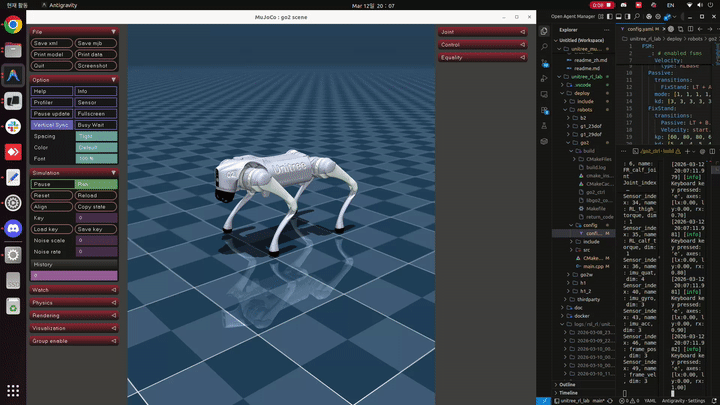
테스트 결과 현실에서와 마찬가지로 mujoco상에서도 로봇이 움직이지 않는 것을 확인하였다… 앞으로는 mujoco에서 무조건 테스트를 통과한 모델만 depoly하는 것이 좋을것 같다.
This post is licensed under CC BY 4.0 by the author.