9월 8일 사수님 미팅
superpoint + superglue 기능 추가
HLOC (Hierarchical-Localization)
[extract.py](http://extract.py/) (super point 추출)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
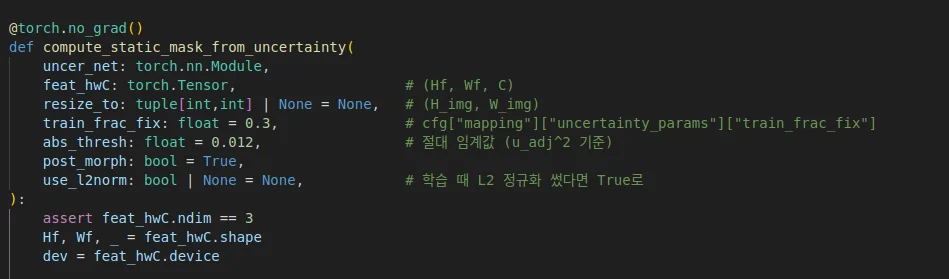
@torch.no_grad()
def _extract(self, img_bgr: np.ndarray):
"""
Run hloc.SuperPoint. Returns dict with:
kpts: (N,2) [x,y], desc: (N,C), scores: (N,)
"""
image = self._to_gray_tensor(img_bgr).to(self.device) # 1x1xH xW
feats = self.sp({"image": image})
# hloc returns 'keypoints': [B, N, 2], 'descriptors': [B, C, N] or [B, N, C] depending on extractor
# SuperPoint in hloc returns descriptors as [B, C, N]. We convert to [N, C].
kpts = feats["keypoints"][0] # (N,2)
scores = feats["scores"][0] # (N,)
desc = feats["descriptors"][0] # (C,N)
# squeeze 배치 차원
if desc.dim() == 3:
desc = desc.squeeze(0)
# ---- 여기서 항상 (N, C) 로 맞춤 ----
N = kpts.shape[0]
if desc.shape[0] == N:
# already (N, C)
pass
elif desc.shape[1] == N:
# (C, N) -> (N, C)
desc = desc.transpose(0, 1).contiguous()
else:
raise ValueError(f"Unexpected descriptor shape {tuple(desc.shape)} vs N={N}")
return kpts, desc, scores, image
- 입력 : 쿼리 bgr 이미지, ref bgr 이미지
- 출력 : descriptor & key point
[match.py](http://match.py/) (쿼리이미지와 ref 이미지 superpoint를 superglue로 비교)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
@torch.no_grad()
def match(
self,
img1_bgr: np.ndarray,
img2_bgr: np.ndarray,
mask1: Optional[np.ndarray] = None,
mask2: Optional[np.ndarray] = None,
):
# 1) SuperPoint features
k1, d1, s1, im1 = self._extract(img1_bgr) # k1: (N1,2), d1: (N1,C)
k2, d2, s2, im2 = self._extract(img2_bgr) # k2: (N2,2), d2: (N2,C)
if k1.shape[0] < 8 or k2.shape[0] < 8:
return np.empty((0, 2), np.float32), np.empty((0, 2), np.float32), 0
# 2) Optional static masks
k1, d1, s1 = self._apply_mask(k1, d1, s1, mask1)
k2, d2, s2 = self._apply_mask(k2, d2, s2, mask2)
if k1.shape[0] < 8 or k2.shape[0] < 8:
return np.empty((0, 2), np.float32), np.empty((0, 2), np.float32), 0
# 3) SuperGlue matching (hloc expects batched inputs)
data = {
"keypoints0": k1[None], # 1xN1x2
"keypoints1": k2[None], # 1xN2x2
"descriptors0": d1[None].transpose(1, 2), # 1xCxN1 (SuperGlue in hloc expects CxN)
"descriptors1": d2[None].transpose(1, 2), # 1xCxN2
"scores0": s1[None], # 1xN1
"scores1": s2[None], # 1xN2
"image0": im1,
"image1": im2,
}
out = self.sg(data)
matches0 = out["matches0"][0] # (N1,) indices in [0..N2-1] or -1
valid = matches0 > -1
if valid.sum() < 8:
return np.empty((0, 2), np.float32), np.empty((0, 2), np.float32), 0
idx1 = torch.where(valid)[0]
idx2 = matches0[valid]
pts1 = k1[idx1].detach().cpu().numpy().astype(np.float32)
pts2 = k2[idx2].detach().cpu().numpy().astype(np.float32)
return pts1, pts2, pts1.shape[0]
- 입력 : 쿼리 superpoint, ref superpoint
- 출력 : point
최종적으로 dinov2 feature의 cosine similiarity와 geometrical 검증 점수(inlier ratio)를 weighted sum 한 최종점수로 retrieval 순위를 최종 rerank한다.
→ 기하학적 검증의 가중치를 조정하여 비슷한 이미지 지만 기하학적 검증 조건이 위배된다면 최종후보에서 탈락시킬 수 있다.

uncertainty mask 적용 시도
IDEA
coarse retrieval된 ref image와 query image의 dinov2 feature에 uncertainty mlp를 통과시켜 동적 객체를 잡아내는 mask를 씌운다 → 동적 물체에서는 superpoint + superglue의 geometrical verification을 적용하지 않는다.
mlp 출력값의 평균,분산 등의 분포를 분석하여 임계값 이하의 픽셀들은 적적 객체로 255, 임계값 이상의 픽셀들은 동적 객체로 0의 마스크를 만든다.
쿼리이미지 에서의 mask


ref 이미지에서의 mask



- 이상한 벽면을 동적으로 잡거나 사람의 형상에 맞지 않는 곳을 동적으로 표현하는듯 mlp의 출력값이 robust하지 않다는 것을 확인하였다. → 현재는 적용 x
GT pose 추출
ROS bag에서 /pose 토픽과 /left_camera/image_raw 의 싱크를 맞춰서 5 frame 마다 추출

- 이후 생성된 1 ~ 1700까지의 프레임중 짝수 프레임을 map 제작에 사용 , 홀수 프레임을 쿼리 이미지로 사용(known GT pose)
- 약 870장으로 map을 생성 → 짝수프레임 870 장은 gt pose와 map pose를 둘다 가지고 있다.
- 약 870 장의 쿼리 이미지 확보
- Frame 171.png 쿼리이미지로 사용하엿다면 168, 170, 172, 174
- 짝수 프레임의 zed camera pose (gt pose)에서 map pose로의 변환을 구해낸다.
- 쿼리이미지의 gt pose에 해당 변환을 적용 후 vggt로 찾아낸 카메라 포즈와 비교
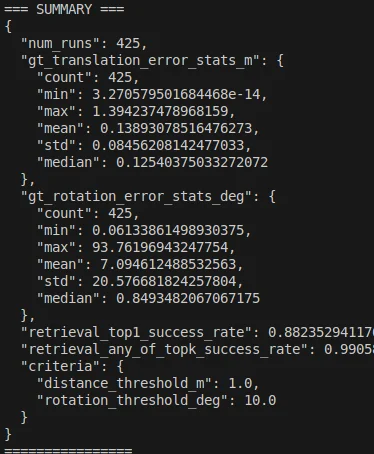
- 쿼리 이미지의 step을 4로 설정하여 약 200 장의 결과물을 분석
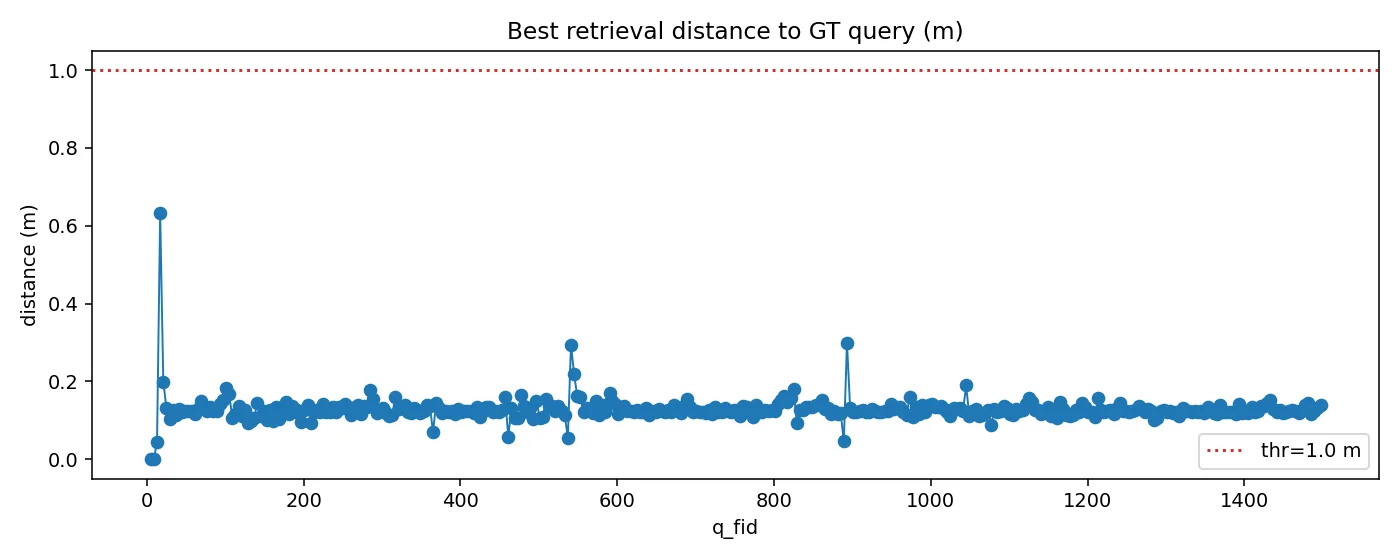
- gt 와의 차이에서 실패기준을 설정
- translation : 1.0m
- rotation : 10°
best retrieval pose
Worst retrieval pose
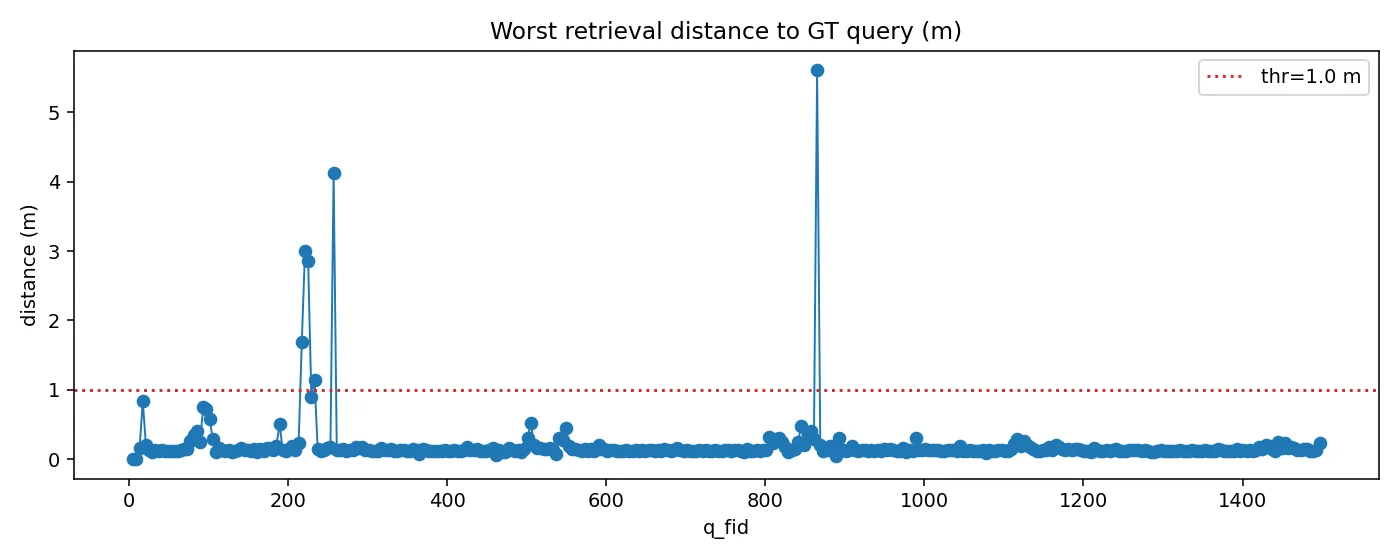
rotation error
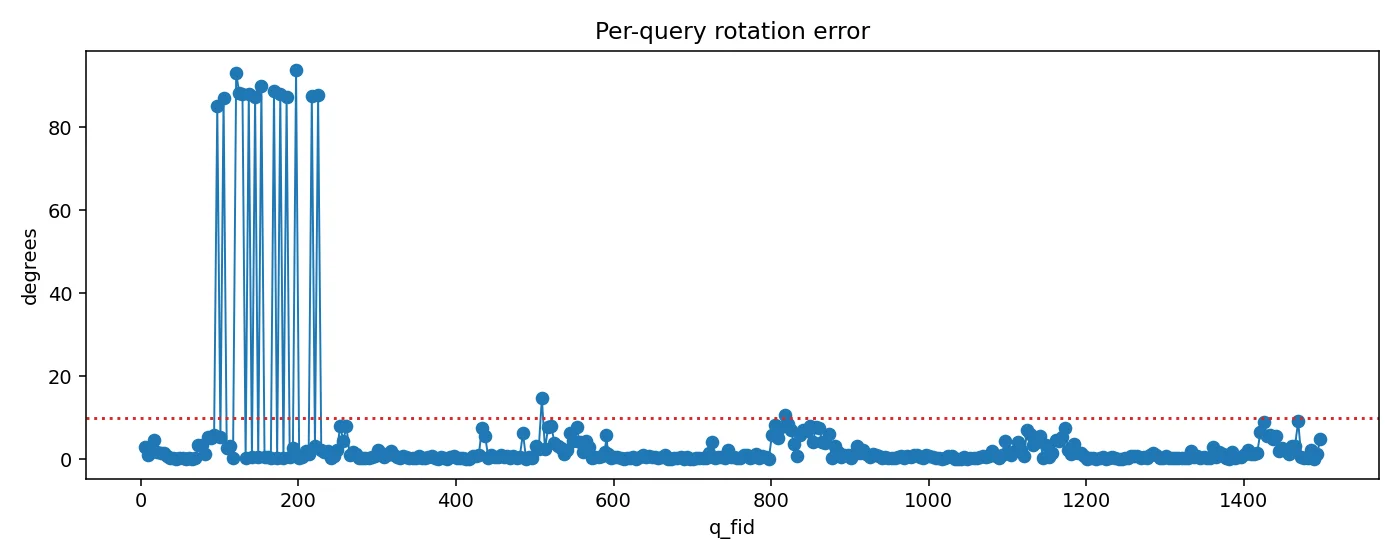
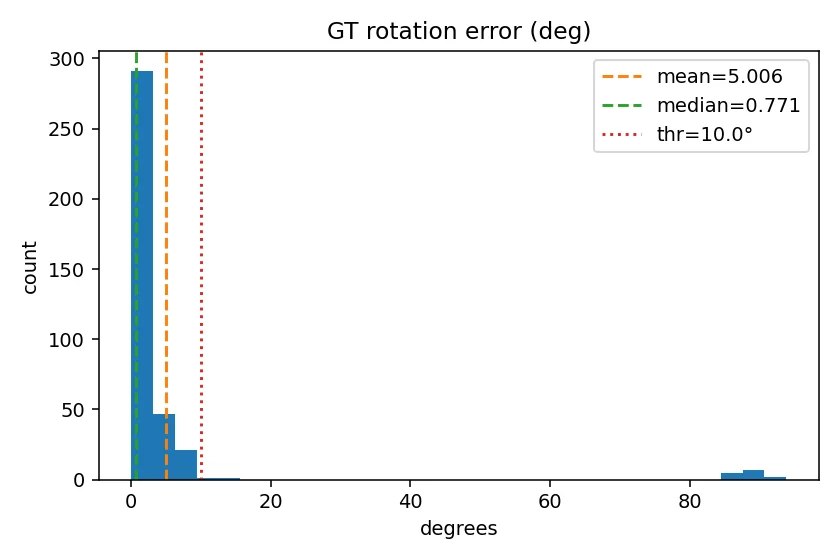
translation error
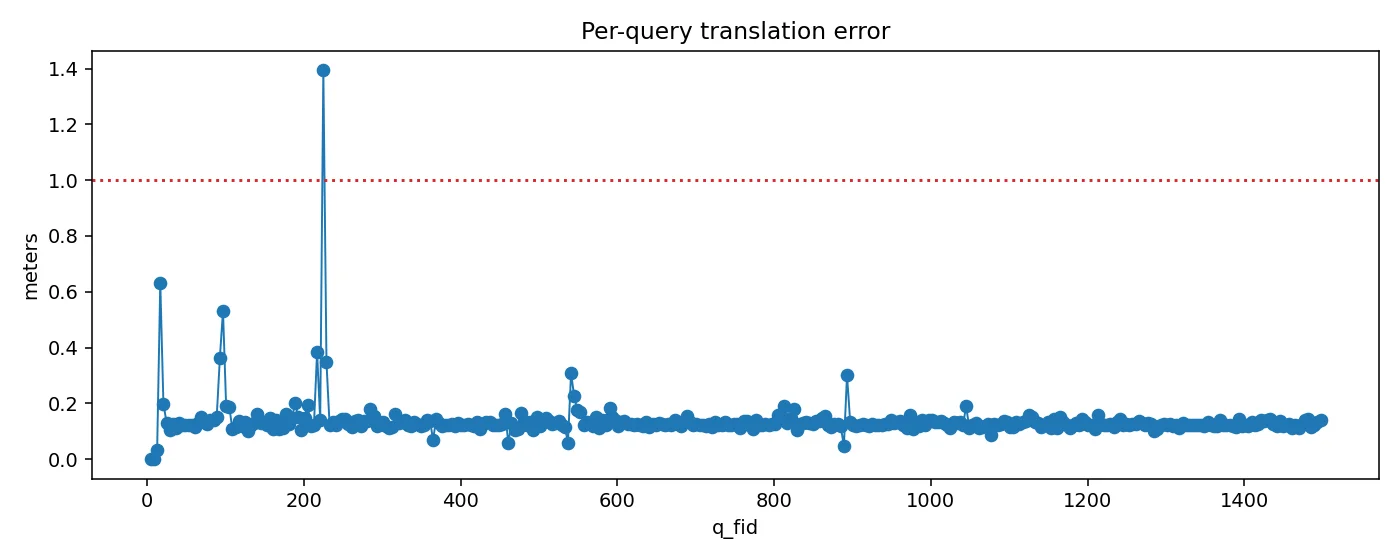
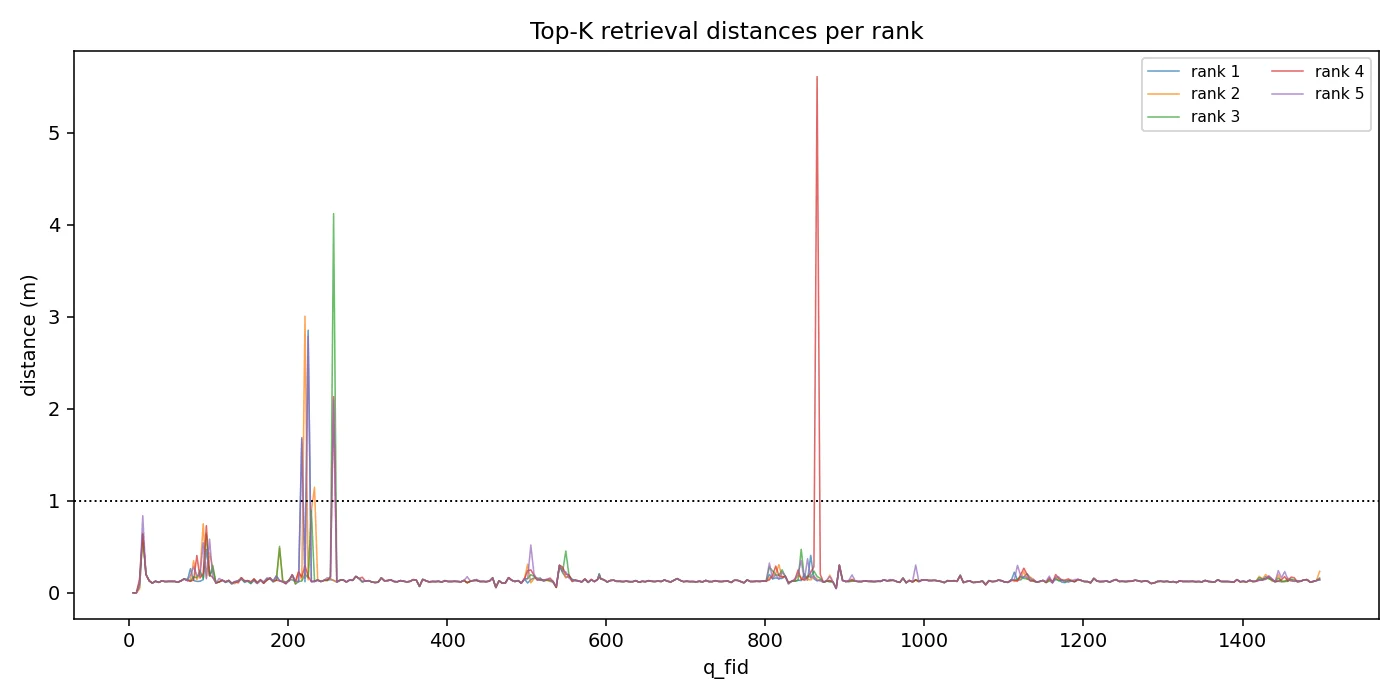
아직은 top k retrieval 이미지가 완벽성을 보장하지는 않는 모습이다.
개별 결과물 분석
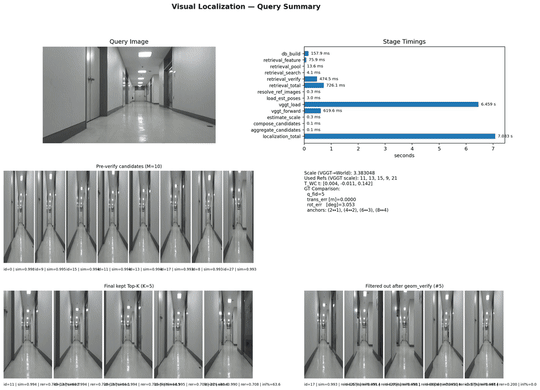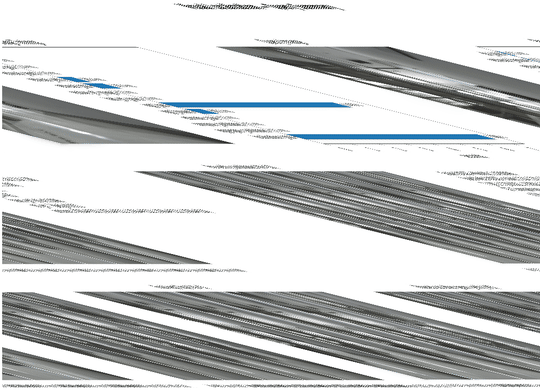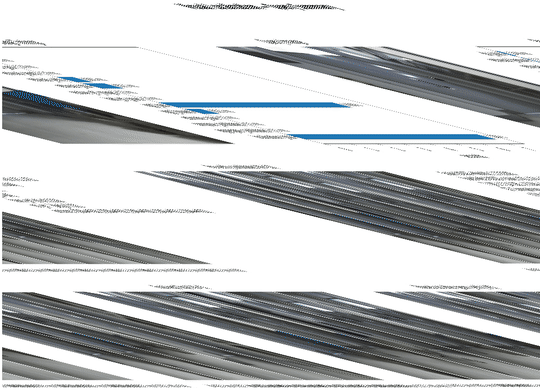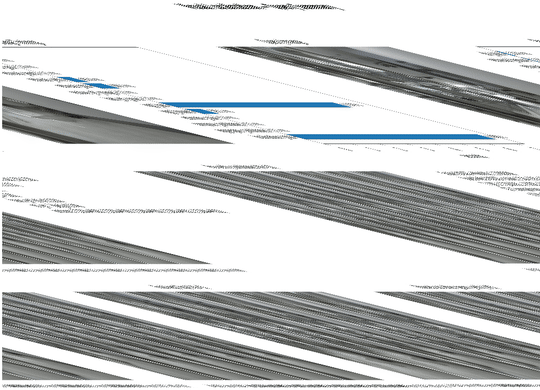



남은 과제

- 동적물체의 영향을 줄일 수 없었다. → retrieval image에도 동적 물체가 들어있다.
새로운 실험
새로운 데이터 셋으로 다시 실험해볼것 (정확한 known GT)
남은 시도들 vggt 없애고 superpoint+superglue로 찾은 init pose를 map상의 가우시안으로 최적화 하여 최종 pose찾기
- 사전 구축된 Gaussian 맵 고정 + 단일 쿼리 이미지의 포즈 (R,t) 만 미세최적화
- 이미 wild gs 에서 제공하고 잇는 기능으로
uncertainty mask 적용
가우시안 map 을 load해서 retrieved image의 depth feature(depth image)와 L1 loss구해보기 (동적물체가 있다면 L1 loss가 크게 나온다.) → 쿼리이미지에서는 동적물체를 거를수 없지만.. ref이미지에 동적 물체가 포함되지 않는 것만 해도 좋다.
- 15분 정도의 발표
- 어떤 테스크, 필요성, 내가 맡은 역할, 어떤 센서 인풋, 방법론 선택의 이유
- 시도해봤지만 실패한 것은 제거
- 발표자료 피드백
- 다음주 월요일 중에 사수님께 예비 발표
여러가지 모델에서 강점이 되는 부분을 적용해서 새로운 프레임워크를 짜냇다 (contribution)
최적화
새로운 bag file로 결과물(야외, feature 수가 적다) (오늘 내로 결과 보기)